This is a simple story about how @haydarkie (the little guy) was able to notch up an incredible victory. He claimed his data back from the electricity companies. We’ll show you the steps he took to get his energy data and save big dollars on his energy bill.

|
| These old style meters only report your electricity once in three months. Smart meters record monitor your electricity every half hour. |
Do you have a smart meter?
Families commonly ask “How do I know if we have a smart meter?” The answer is that you are notified well in advance by your retailer that the installation will take place, and information will be left for you in your mailbox following the installation. Our story begins with the installation of a smart meter at the little guy’s family house.
Why is the data valuable?
Having worked in the industry, the little guy knew that the smart meter data was extremely valuable. With it he could shop around and get a better deal on his electricity – saving up to $100 / year on his bill. He can also see when he uses the most electricity, and whether or not it is during the most expensive part of the day, where customers are slugged double the price [1].
Here is how he got an Excel Spreadsheet of the valuable smart meter output emailed to him directly every quarter.
Contact his electricity company by email
Let them know you have a smart meter installed, you are a happy customer and would like to have regular access to your energy usage so you can save on your energy bill.
Here are the contact details of some of the retailers:
- Red Energy: enquiries@redenergy.com.au
- Origin Energy: https://www.originenergy.com.au/3244/Interval-meter-data-request
- Tru Energy: https://secure.truenergy.com.au/customerforms/LodgeEnquiry.aspx
- AGL: https://online.agl.com.au/enquiry_form.do
Bear in mind many retailers haven’t had a great deal of experience with smart meters yet, and may not have the systems in place to send you data in a timely manner.
Gently remind them of their obligations under the Retail Code
The little guy got pushback from his retailer who claimed there was no requirement to send data more than once per year. That was the old rule, now there is a new rule that says they must provide whenever you request it and no mention of payments being necessary. Be brave, ask for them to send your data every day. For them, sending it once a month (by comparison) is a good compromise.
What can you do with your data?
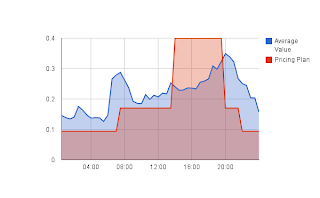.png)
|
| Do you use electricity during the most expensive part of the day? [full size →] |
Run a chart like the one here showing the ‘average value’ which is just your daily electricity use and your retailer’s time of use pricing plans in red. The huge jump in the red line is where you’ll pay the most to your electricity company.
Shop your data around, get together with 30 or so other little guys and form a cartel. You can shop the business of 30 people better than you can individually. This is what the big players like 7/11 and McDonalds do to save a fortune on their electricity costs.
Do you have any success stories about getting your data? Do you want to see your family or small business energy use on a chart like the one above? Leave a comment or email us directly at hello@whit.com.au.
[1] time of use pricing. Most of you won’t be on a time of use pricing plan yet because many retailers have been slow to introduce these plans. Your current plan is likely to be one where you pay a flat rate (say 21 cents / kWh) all day and all year round – even during winter when the market prices for electricity is low and your retailer makes a fortune from you.
With the time of use plans you pay 10 cents / kWh over night, 18 cents during most of the day and 40 cents in the afternoon. “Complicated?”, yes it is complicated, but you could save a lot of money every year if you avoid using electricity during the afternoon. The red line in the chart above shows the price difference throughout a day. I have heard that these plans are a year or two away and seasonal pricing may take even longer to introduce.

![[full size →]](http://4.bp.blogspot.com/-ln19fXpQo9I/T4o4W6TQCLI/AAAAAAAAAGM/Yvp0-fhnoJA/s1600/chart_1(1).png){kind=link}